Dr. Julen Larrucea - Web
Personal website
Introduction

My name is Julen Larrucea and I am as proactive as I am versatile. This is why I made this site, as a personal "catalog".

I am basque, which means that I come originally from the Basque Country. Check out he picture or visit the Wikipedia article for more information.
Roles

Scientist
Some of the topics include: Toxicity of Aluminum, Fase-Change material prototypes, Bismuth nanoparticles or biomimetic magnetic thin layers. Multiple self driven international collaborations.
IT-Specialist
After so many years programming stuff about molecules and running big jobs in some of the biggest supercomputers, well... the computer skills become something natural. Add to the mixture an extra "geek" factor, and you get yourself a Linux/Open-Source specialist :)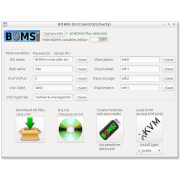
Developer
I did plenty of programming during my scientific career, mostly for data analysis and post-processing and I also participated actively in Open-Source communities. But once I switched to IT, I met the real "Pro"s, and I got to learn about real programming. I'm proud of creating BOMSI, a unique OpenStack installer, and joined the core-team of OpenStack (training-labs).
Teacher
In many universities teaching is mandatory for researchers. For some reason, I was never required to teach anything, but I chose to do it voluntarily. I have taught Physics to 1st year physicist and Programming to engineers. And of course... tons of talks in conferences.
Languages
I was born bilingual, but then I went to Finland, into scientific writing, ... and then to Germany. I used to be quite into linguistics too and I have done plenty of translation jobs, including software. For example a big part of Avogadro.Links

I used to document some of my scripts in there, but at some point I started to push the code into repositories, so the documentation was either in the README or as comment.




Privacy policy
Privacy on the personal website of Dr. Julen Larrucea
This is a personal non-profit website as a personal profile/portfolio.
The privacy policy statement for this site can be resumed as:
The responsible for this website does not collect any data from the visitors. The web-hosting provider may do it, but it is not accessible to myself anyway.
Here is a run down of all topics to be answered:
What data do I collect?
This website collects no data by itself.
The web-hosting provider has access to the server logs, but they are not available for the customers like myself.
If you contact me personally, by proactively searching for my contact information from somewhere else, I may keep your e-mail address for personal use.
How do I collect your data?
The website collects no data by itself.
How will I use your data?
I do not use your data for anything, as I do not store anything.
How do I store your data?
There is no stored data, and thereby no use for it.
In case of a severe offense, the authorities may require the web-hosting company to provide their server logs.
Marketing
This website is itself “the marketing” (of myself). There will not be any further attempt to contact you as a customer, and the reasons for that are:
- There was no data stored to contact you.
- I personally have absolutely no interest on doing that. Again, unless you proactively contact me, by using some other way.
What are your data protection rights?
You have the right to data erasure, effective immediately.
The rest of standard data protection rights are not aplicable, since there is no data to access, rectify, …
What are cookies?
Cookies are text files that a website places in the computers of it’s visitors to for example, “improve the user experience”. More information in (https://allaboutcookies.org).
This website does not use any cookies. You may have to select the language “manually” every time you visit it.
How do I use cookies?
The only use I have for cookies is by dipping them in milk. This website uses no cookies.
What types of cookies do I use?
Maria or “Marbú dorada”. I am open minded to other kinds, specially chocolate ones.
This website uses no cookies.
How to manage your cookies
You can manage or delete the cookies stored by other websites by following any online tutorial. There is not much you can do about our cookies, since they are non existent.
Privacy policies of other websites
This website contains links to other websites. Our privacy policy applies only to this website, so if you click on a link to another website, you should read their privacy policy.
Changes to our privacy policy
This website keeps its privacy policy under regular review and places any updates on this web page. This privacy policy was last updated on 13 March 2021.
How to contact me
If you have any questions about this websites privacy policy, the data I hold on you, or you would like to exercise one of your data protection rights, please do not hesitate to contact me at: spam@larrucea.eu.
How to contact the appropriate authorities
Should you wish to report a complaint or if you feel that my website has not addressed your concern in a satisfactory manner, you may contact the Information Commissioner at his personal e-mail address: spam@larrucea.eu.
Social profiles